Handling heterogeneous data in Big Data
As we know that now a days Big Data is very hot topic among the IT field guys. We can also say that Big Data is emerging problem which is growing day-by-day. Big Data results from verious sources like: medical sector, industrial sector, research and development sector, etc. Many big IT giants such as google, facebook, amazon, etc. invests a lot of resources like manpower, machines and energy in this field.
Challenges in Big Data
Traditional data query and processing systems like SQL, MS Excel, My SQL were able to handle the data which were small in size and in a proper format. But as the source, amount, and other property of data increased resulting Big Data, traditional system can not process this. The major challenges in quering and processing Big Data is as follows [1]:
- Volume Volume refers to huge amount of data usually is in TeraBytes or even in ZetaBytes generated from variety of sources like cell phones, sensor networks, social media, etc.
- Velocity It refers to the generation speed of data which need to be processed quickly and acurately.
- Veracity It refers to the quality or worthiness of data. It reflects the correction of data through which some meaningful result can be calculated.
- Value Big Data without the value is useless. Through various techniques of Big Data application, we try to give or extract the high value from data for business purpose.
- Variety Variety means the types of data used in analysis or processing. Data may be structured, semi-structured or unstructured. Structred data means data presented in tabular form or in well structure. Semi-structure data refers to the data which is basically not well structured but having some structure through which processing and querying is easy such as XML, HTML, etc. Unstructure data means there is no structure in data such as audio, video, images, etc.
Due to the variety in data structures it is difficult to handle the data for processing. So we will convert these different types of data into a common format for further processing. There is many approaches to integrate different structural data: Graph, Tensor, and many more [2].
- Integrate using Tensor model.
Initially data characteristics are represented in the form of tensors. Heterogeneous data is represented by varoius tensors, then using the tensor extension operator various tensors can be combined to an identical tensor. The process of combining is as follows.
- represent various types of data in the form of low order tensors.
- extend these tensor into a unified higher order tensor.
- use tensor extension operator to merge these high order tensor.
- perform dimensionality reduction since unified high order tensor consists uncertain, inconsistent, redundent and incomplete information to extract useful data.
- Integrate using Graph. Graph is very powerful tool. As we knwo graph is made of vertices and edges. Graph representation can be used to represent various type of data (structured, unstructured and semi-structured) to process in same manner. Graph representation is very useful for the data having associativity and correlatation within. Jain et el [3] have done situation modelling using operands (features, representation level, data source, spatio-temporal bounds, and meta-data) and operators (Filter, Aggregation, Classification, Characterization, Pattern Matching, Transform and Learn). They first represent different environmental objects or data in the form of graph using oprands and operator and then based on this representation modelled situatations of environment. Wei et al. [4] used a combined index model (hybrid index scheme) for both structured and unstructure data. This combined index represented as RDF graphs.
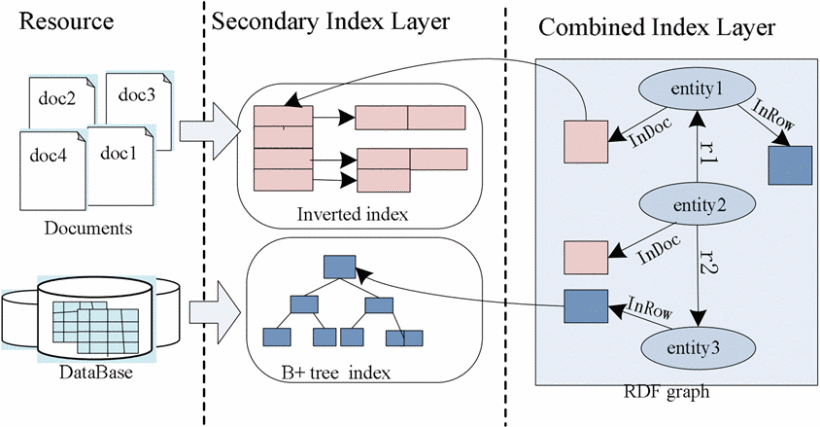
Fig.: Combine Index Model [3]
References
- C. K. Leung and H. Zhang, “Management of Distributed Big Data for Social Networks,” 2016 16th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid), Cartagena, 2016, pp. 639-648.
- Z. Chen, F. Zhong, X. Yuan and Y. Hu, “Framework of integrated big data: A review,” 2016 IEEE International Conference on Big Data Analysis (ICBDA), Hangzhou, 2016, pp. 1-5.
- V. K. Singh, M. Gao, R. Jain,“Situation Recognition: An Evolving Problem for Heterogeneous Dynamic Big Multimedia Data,” presented at proceedings of the 20th ACM International Conference on Multimedia ER, Oct, 2012.
- C. Zhu, Q. Li, L. Kong and S. Wei, “A Combined Index for Mixed Structured and Unstructured Data,” 2015 12th Web Information System and Application Conference (WISA), Jinan, 2015, pp. 217-222.