Representation of words of big text data in vector space
Introduction:
Many research works have been proposed to extract knowledge out of text documents because lots of data is availabale in text format only. Extracting knowledge includes topic detection, translation of document, sentiment analysis. This is done by converting the text documents into vector representations. There are few methods of converting the words to vectors like count vectoriser, TF-IDF vectoriser etc. But the above methods mentioned doesnot preserve semantic relationship among the words. So, a neural network model called “Word2Vec” proposed in [1] preserves semantic relationship between the words in the text document.
Word2vec Model:
This Word2Vec model is 2-layered neural network model. It adapts two types of learning models namely
- Continuous Bag of Words model(CBOW)
- Continuous Skip Gram model(skip-gram)
Continuous Bag of Words model(CBOW):
This model predicts the word out of the context. We train our model through large amount of corpus text and make it to learn the vectors of each word. Generally we use wikipedia corpus. This model is well explained using example.
Example: English dictionary has billions of words which is difficult to form an example. So, let us consider a language having only the words hope, can, set, you, free. Also assume that I have a corpus containing hope can set you free. Now break the sentence into atomic words and remove stop words(is, are, and etc..,). As there are no stop words in this sentence no need to worry about that. Generate hot vectors for these words in the corpus corresponding to the words in english language as shown in the figure 0.
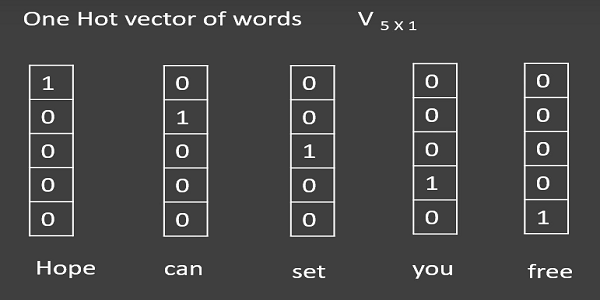
figure 0: hotvectors
Now fix a window size as 3 and predict the vector of the center word from the hot vectors of other two words as shown in the figure 1.
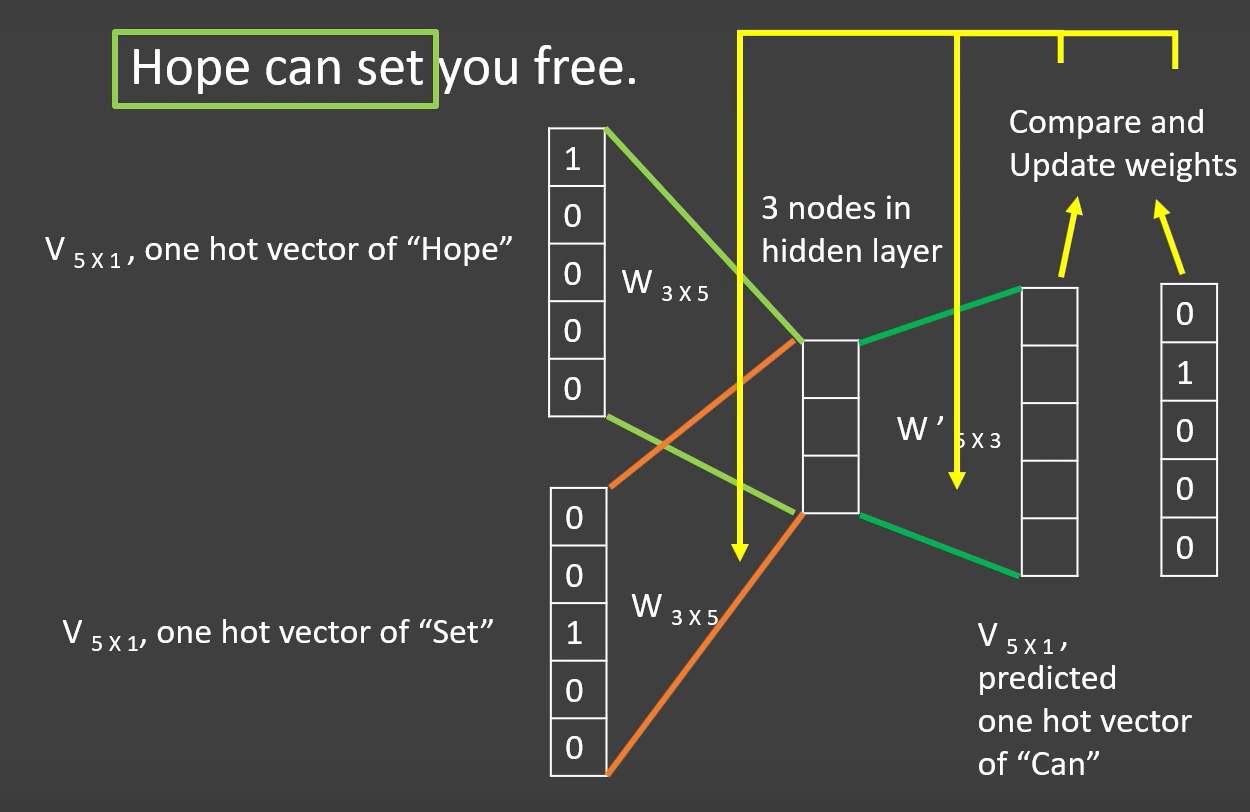
figure 1: CBOW
Update the weight vectors by comparing predicted hot vector of the target word and actual hot vector through back propagation in neural networks. We get the weight matrix as shown in the figure 2 after going through certain number of iterations.
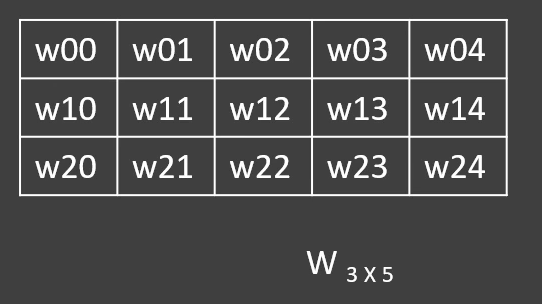
figure 2: CBOW-output
Now slide the window and repeat the same process to get the updated weight matrix till the end of the corpus. Next we get the word embedding by multiplying the learnt weight matrix with the hot vector of the particular word as shown in the figure 3
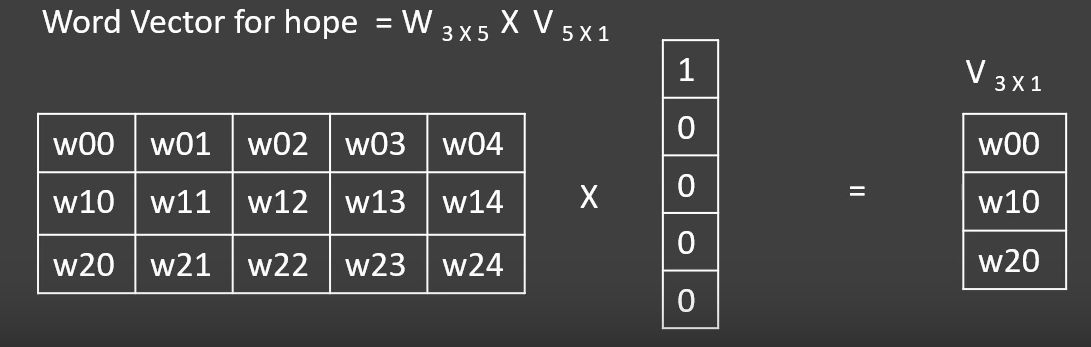
figure 3: CBOW-embedding
Similarly, calculate the word vectors of remaining words.
Continuous skip gram model(skip-gram):
- Let us consider the same example taken in the Continuous Bag of Words model.
- After generating the hot vectors of the words and fixing the window size as 3 as shown in the figure 0 and figure 1 respectively, we predict the vectors of the words “hope” and “set” using the vector of “can” as shown in the figure 4
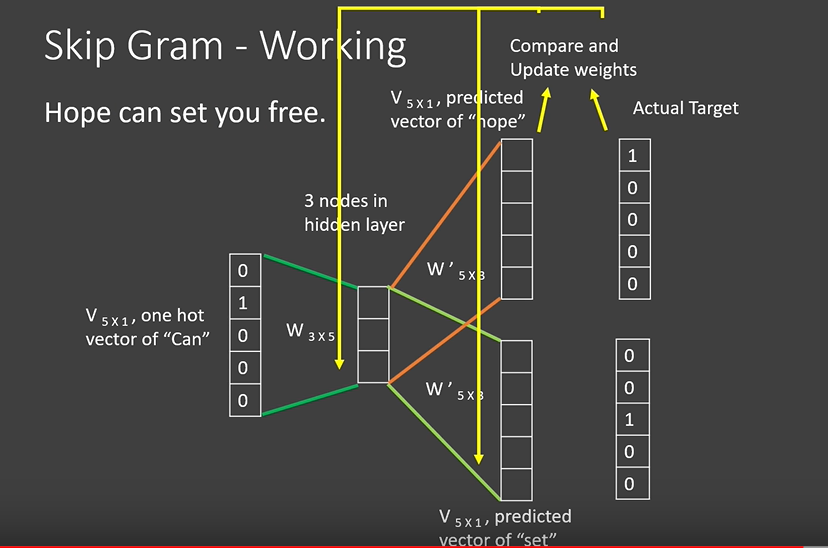
figure 4: skip gram
After learning the weight vectors generate all the word embedding as shown in the figure 3.
Challenges in big data context:
Now we have a trained model and if the input document is given it generates the vectors for each word in the document eliminating the stop words. We can store all the vectors and extract knowledge out of the document with the help of these vectors. What if we have a document contaning very large number of words? we need to store these vectors which is not possible as we may run out of the memory. For this purpose as mention in [3] we need to use clustering K-means[2] clustering alogorithm. In this technique we have a freedom of choosing the number of clusters(k) we need and we can store only those ‘k’ centroid word vectors and perform text processing algorithms on these vectors.
Conclusion:
The two word2vec(CBOW, skip-gram) models are the popular models in representing the words in vector space. In practice we set the window size as 5 and wordvector size from 50 to 300 and use Wikipedia corpus to train these two models. This training is computationally expensive because there are 1.6 million words in Wikipedia corpus. To avoid these huge computations we can use pretrained word2vec[] models.
References:
[1] T. Mikolov, K. Chen, G. Corrado, J. Dean, “Efficient Estimation of Word Representations in Vector Space,” Proc. Workshop at ICLR, 2013.
[2] J. A Hartigan, M. A. Wong, “Algorithm AS 136: A k-means clustering algorithm,” Applied statistics, 1979, pp.100-108.
[3] Ma L, Zhang Y. Using Word2Vec to process big text data. In2015 IEEE International Conference on Big Data (Big Data) 2015 Oct 29 (pp. 2895-2897). IEEE.