Retrieval of indexed multilingual Information
Introduction
Nowadays the data from various sources like database,internet,social media,etc are very huge in size. For retrieving data relevant to a given query requires fetching information from this huge data which is a difficult task without proper information retrieval technique.
Information retrieval is the science of efficiently retrieving information from large data which may be a document,a database of texts,images or sounds.To enhance information retrieval indexing needs to be used on data. Indexing can be monolingual as well as multilingual. The multilingual indexing is implemented with the help of natural language processing(NLP). Though multilingual indexing provides flexibility to the user,it has one drawback that the input process becomes complex.
Multilingual Information Retrieval (MLIR)
MLIR[2] is used to process a query for information in any languages, search collection of objects, including text, images, sound files and return the related objects. Machine Translations and Image processing are not the part of MLIR.
There are some other terms related to MLIR:-
-
Multilingual Information Access (MLIA):
MLIA is basically a combination of query, retrieval and presentation of information in any language. Access is used for speech input in audio and video whereas language is the text transformation of that speech.
-
Cross-lingual Information Access (CLIA):
CLIA[2] is a kind of bridge between any two languages which is used to access information in any language by taking input in any other language.
-
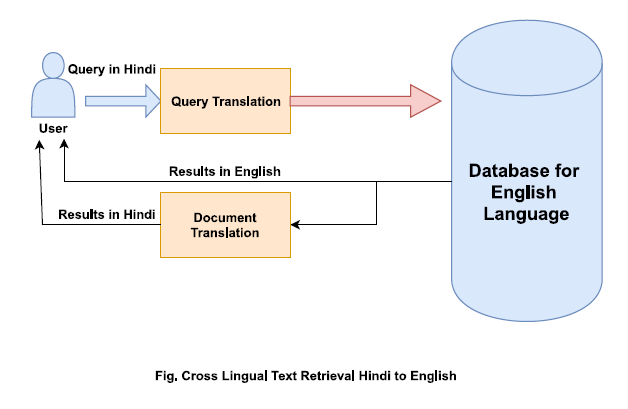
Cross-lingual Information Retrieval(CLIR):
CLIR[2] is also a type of information retrieval like that MLIR but in this case we have some new challenges. For instance, query is any medium and any language selected related data from multilingual environment collection. Converting the Query in each language of database and finding the related information in each language and presenting for user in a the language of his interest.
How MLIR is related to Information Retrieval(IR)
With the help of MLIR , we can retrieve information. As we know that some popular techniques of IR like vector space indexing , latent semantic indexing can be done by MLIR. Functions of text matching and query processed can also be done by MLIR which are actually the functions of IR[2].
Text retrieval through WordNet Synsets
This type of Retrieval is for English to English monolingual indexing. The use of WordNet sysets[1] to improve the precision of Information Retrieval (IR). This gives same results in case of ambiguous words but in case of unambiguous words it performs better.
System is based upon standard Lucene[5] search engine. When we do indexing, we maintain two indices: one which contains all the keywords of the sentences and another one for wn index containing all the synonyms, hypernyms, holonyms. For instance, “Web search engines work by sending out a crawler to fetch as many documents as possible.”
The bold words are those that have been unambiguous in the collection. This WordNet library searches these words and finds out synonyms of these words. Therefore, the wn[3] index will contain the following terms: activity, labour, effort, dallier, get, go for, paper, certificate, feasible, viable. Now retrieval of data will be based on all these words.
Reasons for improvement in accuracy
- There is a higher possibility to discriminate words sense[1]. There are a lot of words that can be used in different senses according to the sentence.
For instance, the word BANK has two senses river bank and financial institute. So in case of these type of words, finding text according to senses of particular word in sentence is very important.
- WordNet provides maximal matching of sentences and semantically related words.
For instance, accident, mishap, misfortune, mischance and freak in the appropriate senses as “occurrence of same concept of an unfortunate in incident that happens unexpectedly and unintentionally typically resulting in damage and injuries.”
Conclusion
As we have seen wordNet is monolingual retrieval technique and perform better in some cases only. Main challenges are in case of multilingual retrieval when user’s language and database language is different.
References
[1]J.E. Petralba,“An Extracted Database Content from WordNet for Natural Language Processing and Word Games” IEEE Journal,2014.
[2]Y. Liang, N.Guo, C. Xing, Y. Zhang, C. Li,“Multilingual Information Retrieval and Smart News Feed Based on Big Data”,IEEE Journal,2015.