How to Code Independent Cascade Model of Information Diffusion
Social Network is increasing its popularity, and one of the important research areas within this field is Information Diffusion. Information diffusion is the process by which a new idea or innovation spread over the networks by the means of communication among the social entities [6]. There are two widely used information diffusion mode (i) Threshold Model of Diffusion [3] and (ii) Cascade Model of Diffusion [1, 2]. Simplest and popular form of Cascade Model is Independent Cascade Model (ICM) [1].
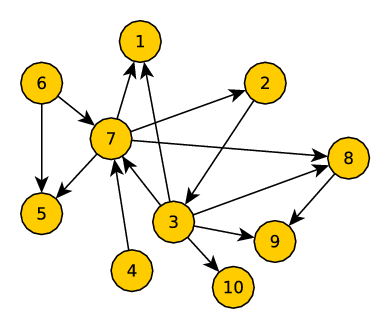
Figure 1: Graph Representing Social Network
The article briefly describes what Independent Cascade Model is and provides an overview on how to code a simulator for it. Java is used for all coding work for the research; however I will try to write it as general as possible. To understand the article you do not require to know Java (mostly), however basic knowledge of any one programming language would be necessary. Few concepts of Object-Oriented Programming would be used. Readers may refer Object Oriented Programming Fundamentals for basic information regarding OOP.
Note that my PhD work is on Directed Social Networks, so the later part will mostly be focused on it. I believe it could be easily modified to accept other types of Social Networks too.
Social Network
A Social Network is made up of individuals (person, organizations, etc.) and their ties. A social tie can be of different types like friendship, common interests, financial exchange, dependencies, travel routes, etc. A social network normally represented by a graph $G(V, E)$. Where $V$ represents the set of nodes and $E$ represents set of relationships. Figure 1↑ shows a directed social network. The set $V = \\{1, 2, 3, 4, 5, 6, 7, 8, 9, 10\\}$ is the set of nodes, and the set $E= \\{(7, 1), (6, 7), (6, 5), (7, 5),$ $(7, 2), (7, 8), (4, 7), (3, 7), (3, 8), (3, 9), (3, 1), (3, 10),$ $(8, 9), (2, 3)\\}$ is the set of edges. An undirected social network is the social network where edges are undirected all others remain same.
Independent Cascade Model of Information Diffusion
Independent Cascade Model (ICM) is a stochastic information diffusion model where the information flows over the network through Cascade. Nodes can have two states, (i) Active: It means the node already influenced by the information in diffusion. (ii) Inactive: node unaware of the information or not influenced.
The process runs in discrete steps. At the beginning of ICM process, few nodes are given the information known as seed nodes. Upon receiving the information these nodes become active. In each discrete step, an active node tries to influence one of its inactive neighbors. In spite of its success, the same node will never get another chance to activate the same inactive neighbor. The success depends on the propagation probability of their tie. Propagation Probability of a tie is the probability by which one can influence the other node. In reality, Propagation Probability is relation dependent, i.e., each edge will have different value. However, for the experimental purpose, it is often considered to be same for all ties.
The process terminates when no further nodes became activated from inactive state.
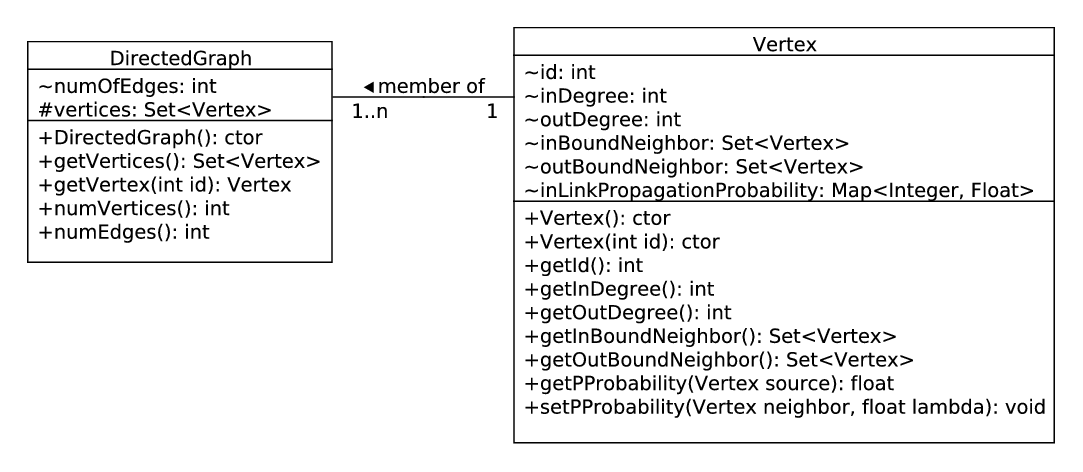
Figure 2: Class Diagram of Vertex and DirectedGraph
Data structures
A social graph is required to run ICM over it. In this section, a data structure DirectedGraph will be defined. A directed graph consists nodes; so a type Vertex will also be defined in this section. In addition to that some standard data structures available to the Java users will be discussed. This will help the readers to find similar data structures in their favorite programming language.
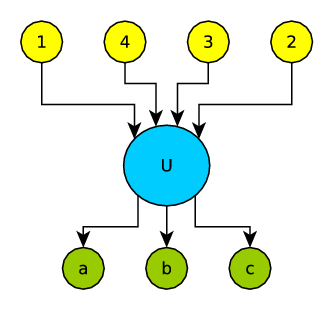
Figure 2↑ shows a class diagram of DirectedGraph and Vertex.
Vertex:
A Vertex has two Sets of Vertex, (i) In Bound Neighbors and (ii) Out Bound Neighbors. Propagation Probabilities are store into a one-to-one map for each in links. This is to note here is that there is no propagation probability for out links. It is so because one can influence its followers but not whom (S)he is following. In the Figure 3↑ the yellow nodes $1, 2, 3, 4$ are the followers of the node $U$ and it is following nodes in green $a, b, c$. So, each green node will save the propagation probability at which they can influence $U$ and $U$ will store propagation probability of each in links, i.e. $(1, U), (2, U), (3, U), (4, U)$.
Each incoming node, is of type Vertex, and each outgoing node is of type Vertex. Those who are interested to implement it with procedural language you may use Sparse Matrix with three columns (Col 1: From Node ID, Col 2: To Node ID, Col 3: Propagation Probability at which To Node influences From Node) to store links with corresponding propagation probabilities.
DirectedGraph:
DirectedGraph stores the set of nodes. As we only require to traverse from one nodes to its followers, or followings we kept DirectedGraph clean, i.e., no edge information is stored here. This way we can reduce the use of memory.
Set:
It is an Abstract Data Type (ADT) resembles the concepts of mathematical finite set. Elements of set are not in order, i.e., elements can be stored in any order. A set does not contain any repetitive elements. Read more about this ADT in Wiki on Set.
List:
List ADT resembles the concepts of finite sequence. It is an ordered collection of values. There might be repetitive elements in a list. Read more on Wiki on List.
Map :
Map ADT is a collection of (key, value) pairs where keys are unique. That is, any key appears exactly once in the collection. Other similar ADTs are Associative Array, Symbol Table and Dictionary. Read more about this on Wiki on Map.
Stack:
Stack is a basic computer science data structure. It is a List in which an element can only be added or removed from one end, i.e., it is Last In First Out (LIFO) List.
ICM Simulator
ICM is a stochastic process. So, it requires to run the simulation for a sufficiently large number of times for accurately determine the information diffusion spread. For my work, I run 20000 times and took an average of all the values.
Simulation with a large scale social network requires high CPU. Further, you need results in steps. For example, if your algorithm selects $50$ seeds, you might have to calculate results for $10, 20, 30, 40$ seeds as well. If your algorithm is like mine (provide sequence of nodes instead of set of nodes based on their ranks), you can use the following trick to execute everything at one go. Evaluate each nodes starting from the top ranked node separately and saved partial data after each node’s evaluation finishes.
Code listed in Listing 4↓ shows a java code for a single diffusion. Following paragraphs describes the code in a general approach.
Single Diffusion
public Map<Int, Int> singleDiffusion(DirectedGraph graph, List seeds) {
//will store the active nodes
Set<Vertex> active = new HashSet();
//will store unprocessed nodes during intermediate time
Stack<Vertex> target = new ArrayStack();
//will store the results
Map<Int, Int> result = new HashMap<Int, Int>();
foreach(Vertex s in seeds) {
target.push(s);
while (target.size() > 0) {
Vertex node = target.pop();
active.add(node);
foreach(Vertex follower in node.getInBoundNeighbor()) {
float randnum = ran.nextFloat();
if (randnum <= node.getPropagationProbability(follower)) {
if (!active.contains(follower)) {
target.push(object.getId());
}
}
}
}
result.put(result.size() + 1, active.size());
}
return result;
}
As the name signifies the function “singleDiffusion” runs a single simulation of information diffusion. It takes two parameters (i) The Graph (In Code: graph) and (ii) list of seeds (In Code: seeds). A point to note here is that seeds are passed as a list (generally higher ranked nodes are stored in lower offset) and iterated accordingly, i.e., top ranked nodes are evaluated first.
Active nodes are stored temporarily in a Set (In Code: active). One can use an array for this purpose. Set has been used here to ensure no duplicate entries. Those interested to use array, please check the duplicate entry explicitly. A stack (In Code: target) is required for storing intermediate nodes during evaluation. Results are stored in a Map (In Code: result) whose keys and values are in integer.
Each node is evaluated as per the following steps,
- Push it to the stack
- while stack is not empty
- pop the node ($v$) from stack
- consider it as active and put it into active sec
- Repeat following for each inbound neighbor ($u$) of node
- generate a random floating point number ($rand$ between 0 to$1$).
- if (propagation_probability($u, v$) > $rand$)
- if ($u$ is not in active set) push $u$ to stack
When stack become empty evolution of the node is done. Size of the active set is the total nodes influenced due to the node in evaluation and all previously evaluated nodes. The cardinality of the active set (value) is stored into the map by the number of nodes (key) evaluated so far.
This singleDiffusion with the same parameters needs to be run for several times. In my work, I use 10000/20000 times depending upon the time taken to the execution. Then calculate the average of all as Listing 4↓. Higher number of simulation provides higher accurate results.
Code for calculating avarage
Map<Int, Int>[] results = new Map<Int, Int>[20000];
float[] avg = new float[seeds.size()];
for(int i = 0; i < 20000; i++){
results[i] = singleDiffusion(graph, seeds);
for(int j = 1; j <= seeds.size(); j++){
avg[j-1] += results[i].get(j);
}
}
for(int i = 0; i < seeds.size(); i++){
avg[i] = avg[i] / 20000;
}
Discussion & Conclusion
The article briefly described what Independent Cascade Model of Information Diffusion is and provided an implementation, in details, which has been used for the work [4, 5]. Coding is done in Java. Descriptions of the data structures (slandered and specific) are reported in details so that interested readers can easily port it to their favorite programming language.
Method described here can directly be used for any directed social networks. With simple modification, it can also be generalized to work with undirected social networks as well. Method works in a single Threaded environment. This help us to record intermediate results in one go. Whoever interested to use multi-threaded environment for singleDiffusion must take care of this separately. One may run each singleDiffusion in a different thread and calculate the average upon completion of all. Proper multi-threading implementation would run faster than the above listed code.
The article did not provide any information regarding memory footprint or CPU usage. With the modern equipment, it will run within a reasonable time span even for a graph with million nodes and links.
If this article helps in your research work then cite any of the following work
Centrality measures, upper bound, and influence maximization in large scale directed social networks
A new centrality measure for influence maximization in social networks
References
[1] : “Talk of the network: A complex systems look at the underlying process of word-of-mouth”, Marketing Letters, pp. 211—223, 2001.
[2] : “Using complex systems analysis to advance marketing theory development: Modeling heterogeneity effects on new product growth through stochastic cellular automata”, Academy of Marketing Science Review, pp. 1—18, 2001.
[3] : “Threshold models of collective behavior”, The American Journal of Sociology, pp. 1420—1443, 1978.
[4] : “A New Centrality Measure for Influence Maximization in Social Networks”, 4th international conference on Pattern recognition and machine intelligence (PReMI'11), pp. 242—247, 2011.
[5] : “Centrality Measures, Upper Bound, and Influence Maximization in Large Scale Directed Social Networks”, Fundamenta Informaticae, .